I’ve been developing an R package that interacts with the Databrary.org API and with Datavyu annotation files stored locally or on Databrary alongside shared videos. If you’re curious, you can download the databraryr package from this GitHub repository: https://github.com/databrary/databraryr.
Like many people in the software world, I’m entirely self-taught. Ok, I took a class in C programming at the U.S. Department of Agriculture’s Graduate School in the year before I applied to graduate schools in cognitive neuroscience. But my R package development skills are entirely self-taught. I must thank the incredibly generous geniuses who have gone before me and who share their code and their talents so freely and openly. Without the almost instant availability of these resources, my progress would be much, much slower.
Developers are an opinionated bunch, and there are at least as many styles (fads?) in software development as their are developers. One style that I have started to try to emulate is ‘test-driven development’. In TDD, the idea is that you create tests for how each part of your package should respond given this or that input. If your tests are through enough and correct, your package should work…at least within the boundaries of what you tested.
For the latest version of the package (0.1.4), I added a bunch of new tests to evaluate several new functions I’ve added to the package. Let’s just say that getting through my own self-designed test battery was challenging. But as a result, the code is cleaner and less buggy than it would be if I hadn’t gone this route.
In the larger sense, TDD is sort of a “plan for the worst” style. I like it because I know it forces me to be more precise and specific than I might otherwise choose to be. Since I’ve been using the databraryapi more often for keeping tabs on what’s going on in the Databrary world, that’s a very good thing.
In case you’re curious what the package can do, check this out:
devtools::install_github("databrary/databraryr")
Downloading GitHub repo databrary/databraryr@HEAD
── R CMD build ─────────────────────────────────────────────────────────────────
* checking for file ‘/private/var/folders/hz/j_rrw69j3pz2xfp4m2jgj__h0000gp/T/RtmpuE9RJI/remotesc05023b4f9ba/databrary-databraryr-2be467f/DESCRIPTION’ ... OK
* preparing ‘databraryr’:
* checking DESCRIPTION meta-information ... OK
* checking for LF line-endings in source and make files and shell scripts
* checking for empty or unneeded directories
Omitted ‘LazyData’ from DESCRIPTION
* building ‘databraryr_0.6.2.9001.tar.gz’
Warning in i.p(...): installation of package
'/var/folders/hz/j_rrw69j3pz2xfp4m2jgj__h0000gp/T//RtmpuE9RJI/filec0503e7734a6/databraryr_0.6.2.9001.tar.gz'
had non-zero exit status
Here is a list of some recently authorized researchers:
databraryr::get_db_stats("people")
# A tibble: 5 × 6
id sortname url institution prename affiliation
<int> <chr> <chr> <lgl> <chr> <chr>
1 12440 Hall <NA> NA Nancy California…
2 12395 Gould <NA> NA Laura NYU Grossm…
3 3738 Laing <NA> NA Cather… University…
4 12393 O'Brien https://www.brunel.ac.uk/peop… NA Justin Brunel Uni…
5 12175 Moriguchi <NA> NA Yusuke Kyoto Univ…
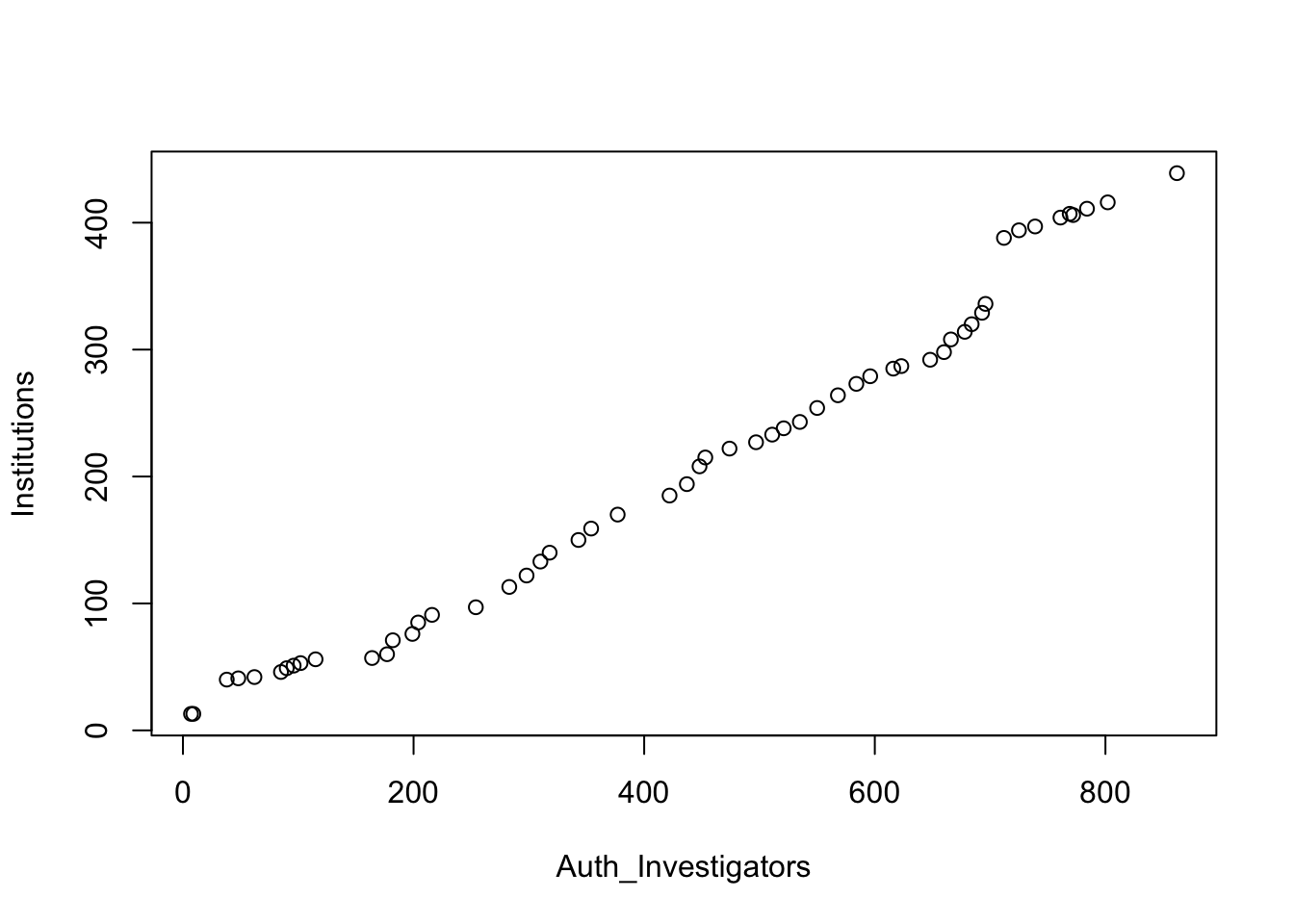
And here is a very simple plot of the growth in authorized researchers and institutions over time:
I’ve said in other places that I think scientists will eventually interact with their data programmatically – via scripts like this – with the data and materials stored in repositories that others can also access programmatically. Furthermore, I think that the philosophy of test-driven development can help make our software AND the results and findings we derive from it more robust and reproducible.